
Spark et Sedona au CASD
Equipe Datascience
Objectifs
- Qu'est-ce que Apache Spark ?
- Traitement de données avec Spark.
- Qu'est-ce que Apache Sedona ?
- Traitement de données spatiales avec Sedona.
Pourquoi utiliser Apache Spark ?
Apache Spark est un outil open source de calcul distribué dédié au traitement et à l'analyse de données volumineuses. Spark est un projet open source administré par la Fondation Apache Spark.
Apache Spark est conçu pour remplacer le précédent outil de calcul distribué Hadoop. Par défaut, Spark réalise les traitements de données en mémoire, pas sur disque.
Spark est maintenant l'un des outils de Big Data les plus utilisés.Les principaux avantages de Spark :
- Vitesse : 100 fois plus rapide que Hadoop MapReduce
- Polyvalence : Batch processing, machine learning, analyse de graphes
- Passage à l'échelle : Machines individuelles, clusters internes, cloud public
- Inter-opérabilité : Avec Python, Java, Scala, R, SQL
- Ecosystème : vaste et mature
Quelques désavantages
- Nécessite d'importantes ressources physiques : CPU, RAM et réseau (en mode cluster).
- Configurations complexes : La mise en place d'un cluster demande une véritable expertise de l'outil.
- Courbe d'apprentissage soutenue : RDDs, DataFrames, plannification par DAG, partitionnement.
- Inadapté aux petits traitements : Le lancement d'une session Spark session et la plannification des tâches ralentit Spark au démarrage.
Les concepts clefs d'une app Spark
Un application Spark contient un un programme pilote et des tâches de traitement de données sur un cluster.
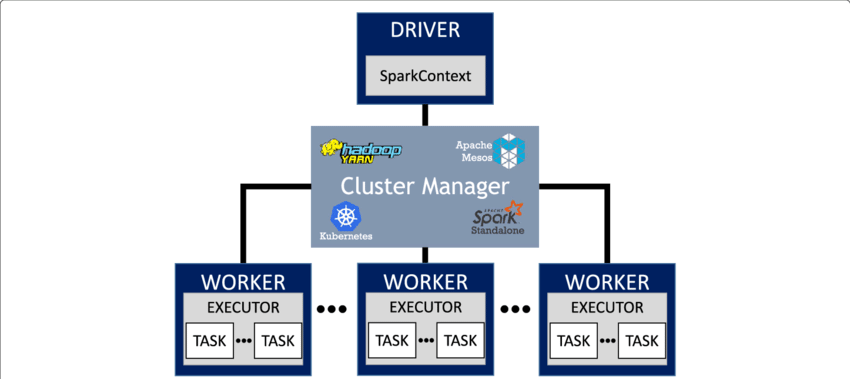
Les concepts clefs de Spark (1) :
- Programme pilote (driver) : Coordonne les workers et le gestionnaire de cluster, traduit les tâches en plan d'exécution, envoie les tâches aux exécuteurs.
- Session & Contexts Sparks : Point d'entrée de l'application Spark, fournit l'accès aux DataFrames, requêtes SQL et configurations.
- Gestionnaire de cluster : Alloue le CPU et la RAM, détermine quelle tâche s'exécute où et quand, surveille les tâches et remplace celles qui échouent.
- Exécuteur : Lance les tâches et sauvegarde les partitions en mémoire ou sur disque.
Les concepts clefs de spark (2) :
- RDD (Resilient Distributed Dataset) : Modèle de données central en Spark. Une collection distribuée et résiliente aux erreurs d'objets immuables.
- DataFrame : Une surcouche du RDD, proposant des opérations de type SQL et optimisée (Catalyst, Tungsten)
- Dataset : Version typée de DataFrame, uniquement disponible avec Scala/Java API.
- Partitionnement : Les données (RDD, DataFrame, Dataset) sont divisées et réparties aux exécuteurs.
Les concepts clefs de Spark (3) :
- Programme pilote : Graph orienté acyclique (DAG) des transformations et des actions.
- Transformations : map, filter, groupBy, etc.
- Actions : show, count, etc... Déclenche l'exécution des transformations précédentes.
- Evaluation paresseuse (lazy) : Les transformations ne sont pas appliquées immédiatement. L'exécution est déclenchée au moment où l'action est demandée : Cela permet à Spark d'optimiser au maximum le DAG.
Les concepts clefs de Spark (avancé)
L'échange (shuffling) de données est la redistribution des données entre les exécuteurs. C'est l'une des opérations les plus coûteuses, contrôler les flux d'échanges est un enjeu majeur de performance.
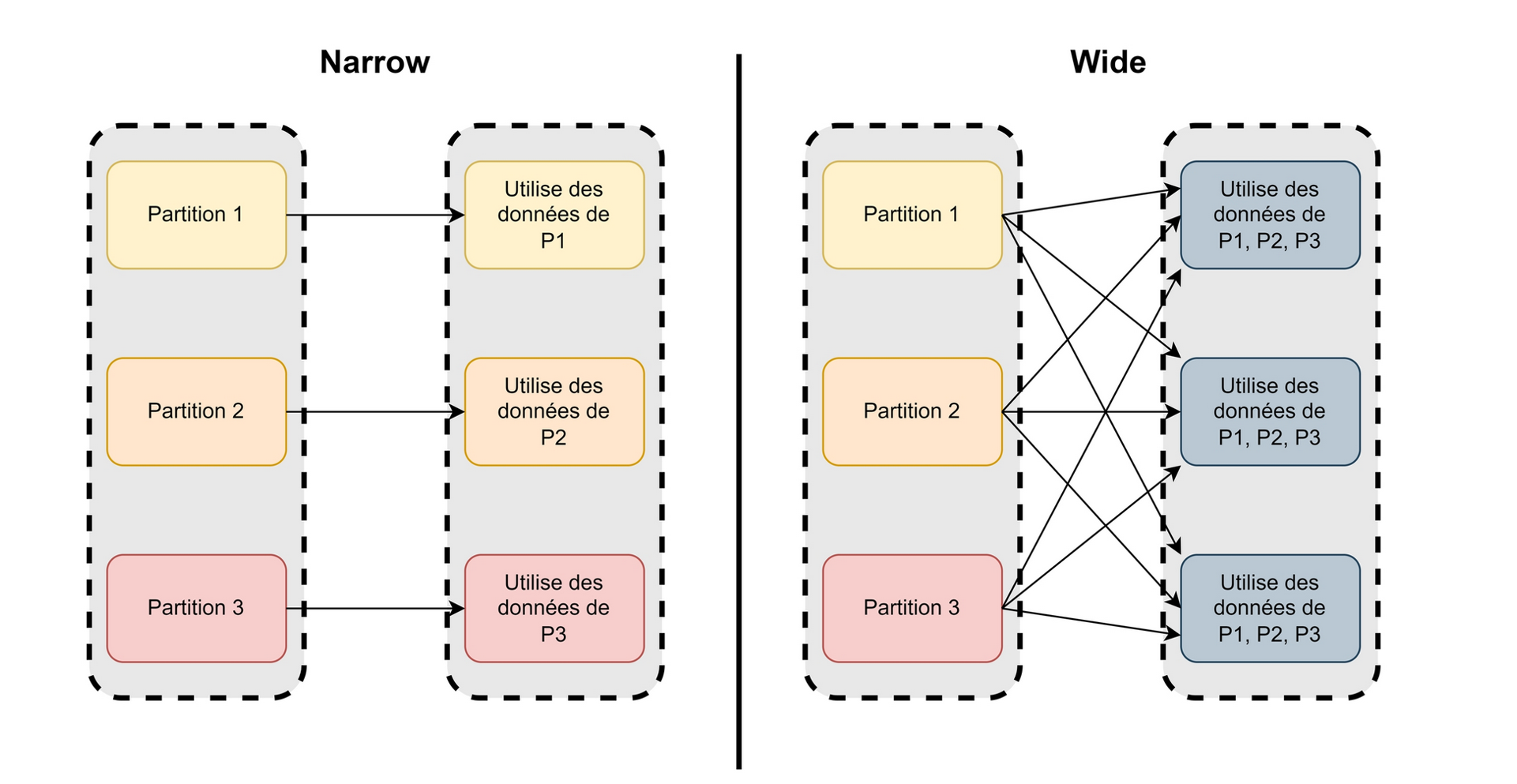
Spark au CASD
- Mode de cluster Spark : local, yarn avec hdfs
- API client Spark: Python, Java, Scala, R, SQL
- Environnement de développement intégré (IDE): vs-code, r-studio, jupyter notebook
- Structure du projet & fichier de configuration : Bonnes pratiques du CASD
Installation de Spark au CASD
Pourquoi utiliser Sedona ?
Apache Sedona étend les fonctionnalités des outils de clustering, comme Apache Spark, Apache Flink, et Snowflake au traitement de données spatiales volumineuses. Il fournit des Spatial Dataset distribués et un moteur de requêtes SQL permettant de charger, de traiter et d'analyser efficacement des jeux de données spatiales distribués sur plusieurs machines.
Le CASD fournit un cluster Apache Spark pour Sedona.
Les principaux avantages de Sedona :
- Vitesse : 10-100 plus rapide que GeoPandas
- Polyvalence : Lecture, ecriture et traitement de données vectorisées et de rasters.
- Passage à l'échelle : Peut traiter des terabytes de données spatiales distribuées sur un cluster.
- Inter-operabilité : Python, Java, Scala, R et SQL
- Bibliothèque de fonctions spatiales très riche : fonctions conformes à la norme OGC, comme ST_Contains, ST_Distance, ST_Intersects, etc.
- Indexation spatiale : Indexation intégrée par R-tree et Quad-tree pour accélérer les requêtes
Quelques désavantages de Sedona
- Consommation de mémoire intensive : Les jointures et l'indexation spatiales peuvent être très consommatrices de mémoire.
- Courbe d'apprentissage soutenue : Nécessite des connaissances à la fois en Spark et en concepts geospatiaux.
- Fonctionnalités limitées pour les Rasters : Le support pour les rasters est basique comparé aux outils spécialisés GIS.
- Fonctionnalités limitées pour la cartographie : Ne dispose pas d'outils de cartographie et de visualisation avancés.
Les concepts clefs de Sedona
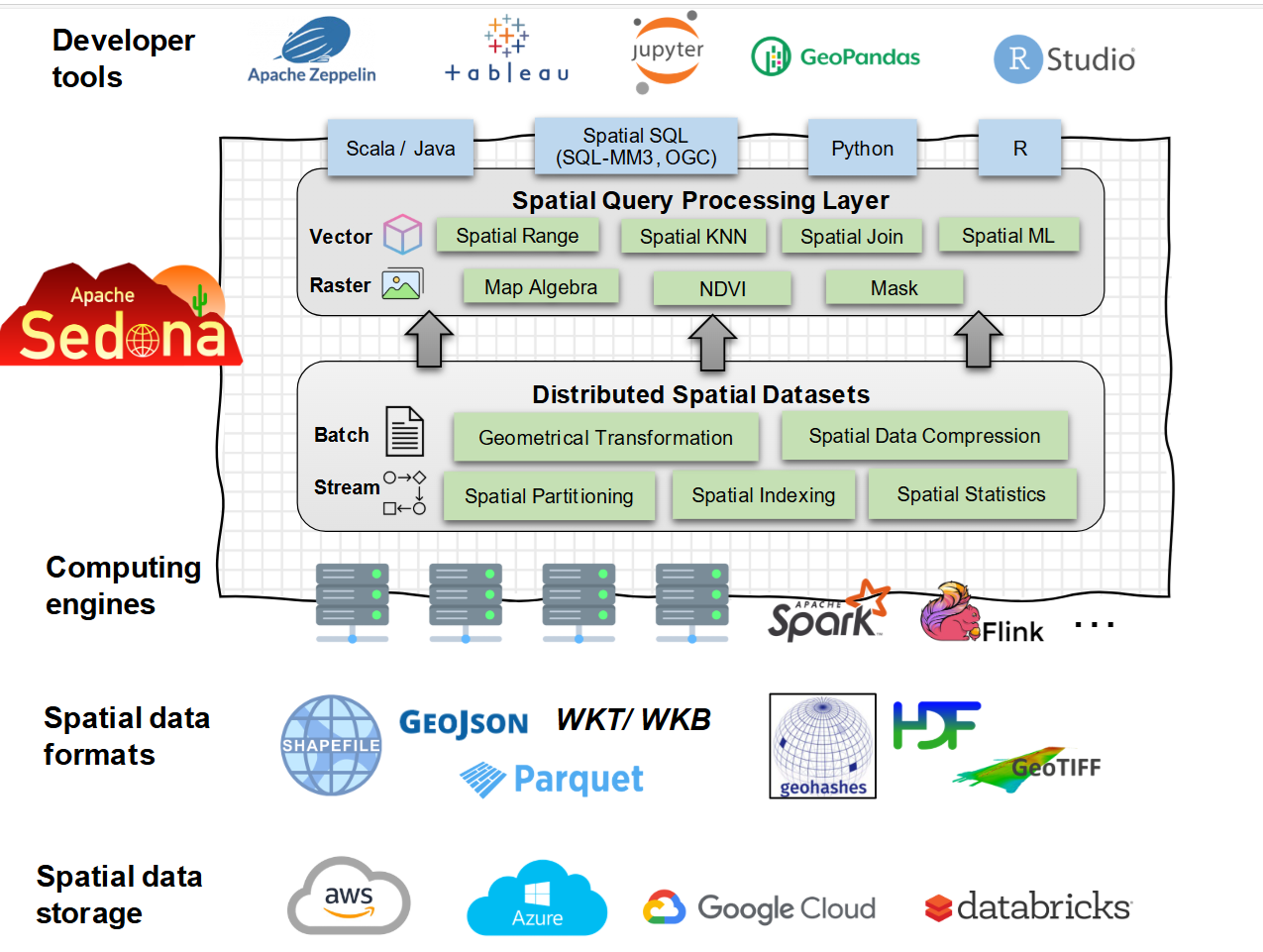
Les concepts clefs de Sedona (Spark)
- Spatial RDDs : Modèle de données central en Sedona pour le stockage de données spatiales
- Spatial DataFrame : Une abstraction des Spatial RDDs pour simplifier leur utilisation
- Fonctions spatiales : Fonctions spatiales prédéfinies
- Partitionnement spatial : Répartit les données sur les noeuds de calcul en utilisant les frontières spatiales pour optimiser les jointures.
- Indexation spatiale : Indexe les colonnes de géométries (R-tree, Quad-tree) pour accélérer l'exécution des requêtes.
Spatial RDDs avec Sedona (Spark)
Sedona ajoute des métadonnées et un index au standard RDD de Spark pour construire des Spatial RDD.
- PointRDD : Modèle de données central pour réprésenter des points
- LineStringRDD : Modèle de données central pour réprésenter des lignes
- PolygonRDD : Modèle de données central pour réprésenter des polygones
Spatial RDDs avec Sedona (Spark)
Sedona ajoute des métadonnées et un index au standard RDD de Spark pour construire des Spatial RDD.
- RectangleRDD : Modèle de données central pour réprésenter des bounding boxes
- RasterRDD : Modèle de données central pour réprésenter des rasters
Spatial Dataframe avec Sedona :
Sedona ajoute des colonnes de type géométries et raster au standard DataFrame de Spark pour construire des Spatial Dataframe. Pour toutes les colonnes spatiales, il introduit des fonctions spatiales SQL (par exemple : ST_Contains, ST_Transform, etc.)
- geometry : Stocke des point, ligne, polygone, liste de polygones
- raster : Stocke des images matricielles, CRS, etc.
Spatial Dataframe avec Sedona :
Sedona ajoute des colonnes de type géométries et raster au standard DataFrame de Spark pour construire des Spatial Dataframe. Pour toutes les colonnes spatiales, il introduit des fonctions spatiales SQL (par exemple : ST_Contains, ST_Transform, etc.)
- geometry sql operators : Plus de 30 fonctions prédéfinies pour les colonnes de géométries
- raster sql operators : Plus de 30 fonctions prédéfinies pour les colonnes de géométries
Sedona au CASD
- Moteur de calcul : Spark
- API client Spark : Python, Java, Scala, SQL, R
- Environnement de développement intégré (IDE) : vs-code, r-studio, jupyter notebook
- Structure du projet & fichier de configuration : Bonnes pratiques du CASD
Installation de Sedona au CASD